Podium data flow¶
In Podium, data exists in three states: raw (prior to tokenization), processed (once the tokenizer and additional postprocessing have been applied) and numericalized (converted to indices).
The data is processed immediately when the instance is loaded from disk and then stored in the Example class. Each instance of an Example (a shallow wrapper of a python dictionary) contains one instance of the dataset. Both the raw and processed data are stored as a tuple attribute under the name of the Field in an Example. You can see this in the SST example:
>>> from podium.datasets import SST
>>> sst_train, sst_dev, sst_test = SST.get_dataset_splits()
>>> sst_train.finalize_fields()
>>> print(sst_train[222])
Example({
text: (None, ['A', 'slick', ',', 'engrossing', 'melodrama', '.']),
label: (None, 'positive')
})
We can unpack the Example class with the bracket notation, as you would a dictionary.
>>> text_raw, text_processed = sst_train[222]['text']
>>> label_raw, label_processed = sst_train[222]['label']
>>> print(text_raw, text_processed)
None ['A', 'slick', ',', 'engrossing', 'melodrama', '.']
>>> print(label_raw, label_processed)
None positive
What are the None s? This is the raw data, which by default isn’t stored in Examples to save memory. If you want to keep the raw data as well (e.g. for future reference), you have to set the keep_raw=True in the corresponding Field.
>>> from podium import Vocab, Field, LabelField
>>> text = Field(name='text', numericalizer=Vocab(), keep_raw=True)
>>> label = LabelField(name='label')
>>> fields = {'text': text, 'label': label}
>>>
>>> sst_train, sst_dev, sst_test = SST.get_dataset_splits(fields=fields)
>>> sst_train.finalize_fields()
>>> print(sst_train[222]['text'])
('A slick , engrossing melodrama .', ['A', 'slick', ',', 'engrossing', 'melodrama', '.'])
We can see that now we also have the pre-tokenized text available to us. In the case of SST this is not very useful because the tokenizer is simply str.split, an easyily reversible function. In the case of non-reversible tokenizers (e.g. the ones in spacy), you might want to keep the raw instance for future reference.
How to interact with Fields¶
In the previous section, we could see that text from the SST dataset is both in uppercase as well as lowercase. Apart from that, we might not want to keep punctuation tokens, which we can also see in the processed data. These are two cases for which we have designed pretokenization and post-tokenization hooks.
As we mentioned earlier, data in Podium exists in three states: first raw, then processed and finally numericalized. You can intervene and add custom transformations inbetween any of these three states. Functions which modify raw data prior to tokenization are called pre-tokenization hooks, while functions which modify processed data prior to numericalization are called post-tokenization hooks. We can see the Field process visualized for the text Field in the following image:
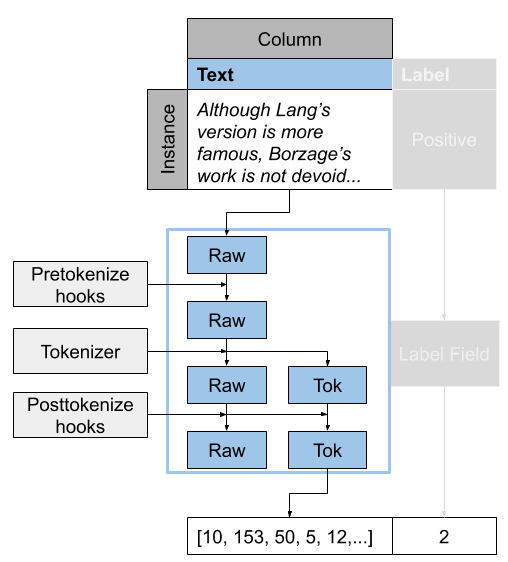
Pretokenization hooks have the following signature:
>>> def pretokenizationHook(raw):
... raw = do_something(raw)
... return raw
Each pretokenization hook accepts one argument, the raw data for that instance, and returns one output, the modified raw data. The raw data is then updated accordingly in the Example instance. Posttokenization hooks follow a similar signature:
>>> def posttokenization_hook(raw, processed):
... processed = do_something(raw, processed)
... return raw, processed
Each post-tokenization hook accepts two arguments, the raw and processed data for that instance and returns two outputs, which are the modified raw and tokenized data. Both of those are then updated in the Example instance for that data Field in each dataset instance.
If we want to define some text processing which requires some external attribute (e.g. storing the list of stop words for removing stop words), our hook can be a class as long as it implements the __call__ method.
>>> class PretokenizationHook:
... def __init__(self, metadata):
... self.metadata = metadata
...
... def __call__(self, raw):
... raw = do_something(raw, metadata)
... return raw
Let’s now define a few concrete hooks and use them in our dataset.
Lowercase as a pretokenization hook¶
We will first implement a pretokenization hook which will lowercase our raw data. Please beware that casing might influence your tokenizer, so it might be wiser to implement this as a post-tokenization hook. In our case however, the tokenizer is str.split, so we are safe. This hook is going to be very simple:
>>> def lowercase(raw):
... """Lowercases the input string"""
... return raw.lower()
And we’re done! We can now add our hook to the text field either through the podium.Field.add_pretokenize_hook() method of the Field or through the pretokenize_hooks constructor argument. We will first define a post-tokenization hook which removes punctuation and then apply them both to our text Field.
Removing punctuation as a post-tokenization hook¶
We will now similarly define a post-tokenization hook to remove punctuation. We will use the punctuation list from python’s built-in str module, which we will store as an attribute of our hook.
>>> import string
>>> class RemovePunct:
... def __init__(self):
... self.punct = set(string.punctuation)
...
... def __call__(self, raw, tokenized):
... """Remove punctuation from tokenized data"""
... return raw, [tok for tok in tokenized if tok not in self.punct]
Putting it all together¶
>>> text = Field(name='text', numericalizer=Vocab(),
... keep_raw=True,
... pretokenize_hooks=[lowercase],
... posttokenize_hooks=[RemovePunct()])
>>> label = LabelField(name='label')
>>> fields = {'text': text, 'label': label}
>>>
>>> sst_train, sst_dev, sst_test = SST.get_dataset_splits(fields=fields)
>>> sst_train.finalize_fields()
>>> print(sst_train[222]['text'])
('a slick , engrossing melodrama .', ['a', 'slick', 'engrossing', 'melodrama'])
We can see that our hooks worked: the raw data was lowercased prior to tokenization, and the punctuation is not present in the processed data. You can similarly define other hooks and pass them as arguments to your Fields. It is important to take care of the order in which you pass the hooks – they will be executed in the same order as you passed them to the constructor, so take care that you don’t modify some aspect of data crucial for your next hook.
We have prepared a number of predefined hooks which are ready for you to use. You can see them here: Hooks.
Special tokens¶
We have earlier mentioned special tokens, but now is the time to elaborate on what exactly they are. In Podium, each special token is a subclass of the python str which also encapsulates the functionality for adding that special token in the tokenized sequence. The Vocab handles special tokens differently – each special token is guaranteed a place in the Vocab, which is what makes them… special.
Since our idea of special tokens was made to be extensible, we will take a brief look at how they are implemented, so we can better understand how to use them. We mentioned that each special token is a subclass of the python string, but there is an intermediary – the podium.vocab.Special base class. The Special base class implements the following functionality, while still being an instance of a string:
Extending the constructor of the special token with a default value functionality. The default value for each special token should be set via the
default_valueclass attribute, while if another value is passed upon creation, it will be used.Adds a stub
applymethod which accepts a sequence of tokens and adds the special token to that sequence. In its essence, the apply method is a post-tokenization hook (applied to the tokenized sequence after other post-tokenization hooks) which doesn’t see the raw data whose job is to add the special token to the sequence of replace some of the existing tokens with the special token. The special tokens are applied after all post-tokenization hooks in the order they are passed to thepodium.Vocabconstructor. Each concrete implementation of a Special token has to implement this method.Implements singleton-like hash and equality checks. The
Specialclass overrides the default hash and equals and instead of checking for string value equality, it checks for class name equality. We use this type of check to ensure that eachVocabhas a single instance of each Special and for simpler referencing and contains checks.
There is a number of special tokens used throughout NLP for a number of purposes. The most frequently used ones are the unknown token (UNK), which is used as a catch-all substitute for tokens which are not present in the vocabulary, and the padding token (PAD), which is used to nicely pack variable length sequences into fixed size batch tensors. Alongside these two, common special tokens include the beginning-of-sequence and end-of-sequence tokens (BOS, EOS), the separator token (SEP) and the mask token introduced in BERT (MASK).
To better understand how specials work, we will walk through the implementation of one of special tokens implemented in Podium: the beginning-of-sequence (BOS) token.
>>> from podium.vocab import Special
>>> class BOS(Special):
... token = "<BOS>"
...
... def apply(self, sequence):
... # Prepend to the sequence
... return [self] + sequence
>>>
>>> bos = BOS()
>>> print(bos)
<BOS>
This code block is the full implementation of a special token! All we needed to do is set the default value and implement the apply function. The default value is None by default and if not set, you have to make sure it is passed upon construction, like so:
>>> my_bos = BOS("<MY_BOS>")
>>> print(my_bos)
<MY_BOS>
>>> print(bos == my_bos)
True
We can also see that although we have changed the string representation of the special token, the equality check will still return True due to the Special base class changes mentioned earlier.
To see the effect of the apply method, we will once again take a look at the SST dataset:
>>> from podium import Vocab, Field, LabelField
>>> from podium.datasets import SST
>>>
>>> vocab = Vocab(specials=(bos))
>>> text = Field(name='text', numericalizer=vocab)
>>> label = LabelField(name='label')
>>> fields = {'text': text, 'label': label}
>>>
>>> sst_train, sst_dev, sst_test = SST.get_dataset_splits(fields=fields)
>>> sst_train.finalize_fields()
>>> print(sst_train[222]['text'])
(None, ['<BOS>', 'A', 'slick', ',', 'engrossing', 'melodrama', '.'])
Where we can see that the special token was indeed added to the beginning of the tokenized sequence.
Finally, it is important to note that there is an implicit distinction between special tokens. The unknown (podium.vocab.UNK) and padding (podium.vocab.PAD) special tokens are something we refer to as core special tokens, whose functionality is hardcoded in the implementation of the Vocab due to them being deeply integrated with the way iterators and numericalization work.
The only difference between normal and core specials is that core specials are added to the sequence by other Podium classes (their behavior is hardcoded) instead of by their apply method.
Custom numericalization functions¶
It is often the case you want to use a predefined numericalization function, be it a Vocabulary obtained from another repository or one with functionality which our Vocab doesn’t cover.
To do that, you should pass your own callable function as the numericalizer for the corresponding Field. Please also beware that in this case, you also need to define the padding token index in order for Podium to be able to batch your data. A common example, where you want to use a tokenizer and a numericalization function from a pretrained BERT model using the 🤗 transformers library can be implemented as follows:
>>> from transformers import BertTokenizer
>>> tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
>>> pad_index = tokenizer.convert_tokens_to_ids(tokenizer.pad_token)
>>>
>>> subword_field = Field("text",
... padding_token=pad_index,
... tokenizer=tokenizer.tokenize,
... numericalizer=tokenizer.convert_tokens_to_ids)
>>> label = LabelField('label')
>>> fields = {'text': subword_field, 'label': label}
>>>
>>> sst_train, sst_dev, sst_test = SST.get_dataset_splits(fields=fields)
>>> sst_train.finalize_fields()
>>> print(sst_train[222]['text'])
(None, ['a', 'slick', ',', 'eng', '##ross', '##ing', 'mel', '##od', '##rama', '.'])
Fields with multiple outputs¶
We have so far covered the case where you have a single input column, tokenize and numericalize it and then use it in your model. What if you want to obtain multiple outputs from the same input text? A common example is obtaining both words and characters for an input sequence. Let’s see how we would implement this in Podium:
>>> from podium import Vocab, Field, LabelField
>>> from podium.datasets import SST
>>> char = Field(name='char', numericalizer=Vocab(), tokenizer=list)
>>> text = Field(name='word', numericalizer=Vocab())
>>> label = LabelField(name='label')
>>> fields = {'text': (char, text), 'label': label}
>>>
>>> sst_train, sst_dev, sst_test = SST.get_dataset_splits(fields=fields)
>>> print(sst_train[222]['word'], sst_train[222]['char'], sep='\n')
(None, ['A', 'slick', ',', 'engrossing', 'melodrama', '.'])
(None, ['A', ' ', 's', 'l', 'i', 'c', 'k', ' ', ',', ' ', 'e', 'n', 'g', 'r', 'o', 's', 's', 'i', 'n', 'g', ' ', 'm', 'e', 'l', 'o', 'd', 'r', 'a', 'm', 'a', ' ', '.'])
You can pass a tuple of Fields under the same input data column key, and all of the Fields will use data from input column with that name. If your output Fields share the (potentially expensive) tokenizer, we have implemented a class that optimized that part of preprocessing for you: the podium.MultioutputField.
The Multioutput Field¶
Multioutput Fields are fake Fields which simply handle the shared pretokenization and tokenization part of the Field processing pipeline and then forward the data to the respective output Fields.
One example of such a use-case would be extracting both word tokens as well as their corresponding part-of-speech tags, both to be used as inputs to a model. For this example, we will still use the SST dataset as a demo, but we will use the spacy tokenizer.
>>> from podium import MultioutputField
>>> import spacy
>>>
>>> # Define hooks to extract raw text and POS tags
>>> # from spacy token objects
>>> def extract_text_hook(raw, tokenized):
... return raw, [token.text for token in tokenized]
>>> def extract_pos_hook(raw, tokenized):
... return raw, [token.pos_ for token in tokenized]
>>>
>>> # Define the output Fields and the MultioutputField
>>> word = Field(name='word', numericalizer=Vocab(), posttokenize_hooks=[extract_text_hook])
>>> pos = Field(name='pos', numericalizer=Vocab(), posttokenize_hooks=[extract_pos_hook])
>>>
>>> spacy_tokenizer = spacy.load('en_core_web_sm', disable=['parser', 'ner'])
>>> text = MultioutputField([word, pos], tokenizer=spacy_tokenizer)
>>>
>>> label = LabelField(name='label')
>>> fields = {'text': text, 'label': label}
>>>
>>> sst_train, sst_dev, sst_test = SST.get_dataset_splits(fields=fields)
>>> print(sst_train[222]['word'], sst_train[222]['pos'], sep='\n')
(None, ['A', 'slick', ',', 'engrossing', 'melodrama', '.'])
(None, ['DET', 'ADJ', 'PUNCT', 'VERB', 'NOUN', 'PUNCT'])
MultioutputFields accept three parameters upon construction, which encapsulate the first part of the Field processing cycle:
output_fields(List[Field]): a sequence of Fields which will map tokenized data to outputs by applying post-tokenization hooks and numericalization.
tokenizer(str | Callable): the tokenizer to use (keyword string or callable function). The same tokenizer will be used prior to passing data to all output Fields.
pretokenization_hooks(Tuple(Callable)): a sequence of pretokenization hooks to apply to the raw data.
After tokenization, the processed data will be sent to all of the output Fields. Note that only the post-tokenization part of the output fields will be used.
Dataset manipulation¶
Dataset splitting¶
It is often the case we want to somehow manipulate the size of our dataset. One common use-case is that our dataset comes in a single split – and we wish to segment it into a train, test and perhaps validation split. For this, we have defined a podium.Dataset.split() function which allows you to split your dataset into arbitrary ratios:
>>> sst, _, _ = SST.get_dataset_splits()
>>> total_size = len(sst)
>>> # Pretend we don't have a test and dev split :)
>>> sst_train, sst_dev, sst_test = sst.split([5,3,2], random_state=1)
>>> print(len(sst_train)/total_size, len(sst_dev)/total_size, len(sst_test)/total_size)
0.5 0.3 0.2
As you can notice from the example – you can define the split sizes as integer ratios and they will be normalized automatically. This type of splitting is done randomly, and there is always the possibility that your splits will have unevenly distributed target labels. We can easily check how evenly are the splits distributed:
>>> from collections import Counter
>>> def value_distribution(dataset, field='label'):
... c = Counter([ex[field][1] for ex in dataset])
... Z = sum(c.values())
... return {k: v/Z for k, v in c.items()}
>>>
>>> print(value_distribution(sst_train),
... value_distribution(sst_dev),
... value_distribution(sst_test),
... sep="\n")
{'negative': 0.47803468208092487, 'positive': 0.5219653179190752}
{'negative': 0.48458574181117536, 'positive': 0.5154142581888247}
{'negative': 0.46965317919075145, 'positive': 0.5303468208092486}
If an even label distribution between your splits is something you desire, you can use the _stratified_ split option by providing the name of the field you wish to stratify over:
>>> sst_train, sst_dev, sst_test = sst.split([5,3,2], stratified=True,
... strata_field_name='label', random_state=1)
>>> print(len(sst_train)/total_size, len(sst_dev)/total_size, len(sst_test)/total_size)
0.5 0.3 0.2
As we can see, the sizes of our splits are the same, but in this case the label distribution is more balanced, which we can validate in a similar fashion:
>>> print(value_distribution(sst_train),
... value_distribution(sst_dev),
... value_distribution(sst_test),
... sep="\n")
{'negative': 0.47832369942196534, 'positive': 0.5216763005780347}
{'negative': 0.47832369942196534, 'positive': 0.5216763005780347}
{'negative': 0.47832369942196534, 'positive': 0.5216763005780347}
Dataset concatenation¶
Another instance where you would want to manipulate datasets is where you have multiple datasets of the same task type and want to train a single model on the concatenation of those datasets. For this case, we have implemented a helper function which concatenates a given list of datasets and creates a new dataset containing all the instances in the concatenated datasets.
There is a certain degree of intervention you need to do here – the concatenated datasets can have different vocabularies, so you either need to be certain that the vocabularies are equal or provide a new Field which will be constructed on the (processed) values of all datasets.
For a simple example, we will take a look at the built-in SST and IMDB datasets:
>>> from podium.datasets import IMDB, SST, concat
>>> from podium import Field, LabelField, Vocab
>>> # Load the datasets
>>> imdb_train, imdb_test = IMDB.get_dataset_splits()
>>> sst_train, sst_dev, sst_test = SST.get_dataset_splits()
>>>
>>> # Luckily, both label vocabularies are already equal
>>> print(imdb_train.field('label').vocab.itos)
['positive', 'negative']
>>> print(sst_train.field('label').vocab.itos)
['positive', 'negative']
>>> # Define a text Field for the concatenated dataset
>>> concat_text_field = Field("text", numericalizer=Vocab())
>>> sentiment_dataset = concat([imdb_train, sst_train],
... field_overrides={"text":concat_text_field})
>>> print(f"{len(sentiment_dataset)} = {len(imdb_train)} + {len(sst_train)}")
31920 = 25000 + 6920
There are a few important takeaways here: (1) the concatenated dataset will only contain the intersection of Fields from the sub-datasets. The intersection is determined by the name of each Field. If one dataset has Fields named text and label, while the other has Fields named text, label and meta, the concatenated dataset will only contain the text and label Fields. (2) the Vocabularies for the Fields with the same name have to be equal. This is, of course, to avoid the issue where the same word maps to different indices between vocabularies. This is achieveable either by using a shared vocabulary in same Fields of the datasets from the beginning or by defining a field_override map, which directs data from the sub-datasets through the new Field.
In the latter case, you can use each sub-dataset on their own with independent vocabularies, while the concatenation will have its own, merged vocabulary.
Bucketing instances when iterating¶
When iterating over NLP datasets, it is common that instances in a batch do not have the same length. This is traditionally solved by padding all instances in a batch to the length of the longest instance. Iterating naively over instances with large variance in length will add a lot of padding.
For this reason, usage of podium.datasets.BucketIterator is recommended. The BucketIterator uses a lookahead heuristic and sorts the instances based on a user-defined sort function. Let’s take a look at a short example:
>>> from podium import Vocab, Field, LabelField
>>> from podium.datasets import SST, IMDB
>>> vocab = Vocab()
>>> text = Field(name='text', numericalizer=vocab)
>>> label = LabelField(name='label')
>>> fields = {'text': text, 'label': label}
>>>
>>> train, valid, test = SST.get_dataset_splits(fields=fields)
>>>
>>> # Define the iterators and our sort key
>>> from podium import Iterator, BucketIterator
>>> def instance_length(instance):
>>> # Use the text Field
>>> raw, tokenized = instance.text
>>> return len(tokenized)
>>> bucket_iter = BucketIterator(train, batch_size=32, bucket_sort_key=instance_length)
The bucket_sort_key function defines how the instances in the dataset should be sorted. The method accepts an instance of the dataset, and should return a value which will be used as a sort key in the BucketIterator. It might be interesting (and surprising) to see how much space (and time) do we earn by bucketing. We will define a naive iterator on the same dataset and measure the total amount of padding used when iterating over a dataset.
>>> import numpy as np
>>> vanilla_iter = Iterator(train, batch_size=32)
>>>
>>> def count_padding(batch, padding_idx):
>>> return np.count_nonzero(batch == padding_idx)
>>> padding_index = vocab.get_padding_index()
>>>
>>> for iterator in (vanilla_iter, bucket_iter):
>>> total_padding = 0
>>> total_size = 0
>>>
>>> for batch in iterator:
>>> total_padding += count_padding(batch.text, padding_index)
>>> total_size += batch.text.size
>>> print(f"For {iterator.__class__.__name__}, padding = {total_padding}"
>>> f" out of {total_size} = {total_padding/total_size:.2%}")
For Iterator, padding = 148141 out of 281696 = 52.588961149608096%
For BucketIterator, padding = 2125 out of 135680 = 1.5661851415094339%
As we can see, the difference between using a regular Iterator and a BucketIterator is massive. Not only do we reduce the amount of padding, we have reduced the total amount of tokens processed by about 50%. The SST dataset, however, is a relatively small dataset so this experiment might be a bit biased. Let’s take a look at the same statistics for the podium.datasets.impl.IMDB dataset. After changing the data loading line in the first snippet to:
>>> train, test = IMDB.get_dataset_splits(fields=fields)
And re-running the code, we obtain the following, still significant improvement:
For Iterator, padding = 13569936 out of 19414616 = 69.89%
For BucketIterator, padding = 259800 out of 6104480 = 4.25%
Generally, using bucketing when iterating over your NLP dataset is preferred and will save you quite a bit of processing time.
Saving and loading Podium components¶
Preprocessing your dataset is often time-consuming and once you’ve done it, you wouldn’t want to repeat the process. In Podium, we cache your processed and numericalized dataset so neither of these computations has to be done more than once. To ensure you don’t have to repeat the potentially expensive preprocessing, all of our base components are picklable.
As an example, we will again turn to the SST dataset and some of our previously used hooks:
>>> from podium import Vocab, Field, LabelField
>>> from podium.datasets import SST
>>>
>>> vocab = Vocab(max_size=5000, min_freq=2)
>>> text = Field(name='text', numericalizer=vocab)
>>> label = LabelField(name='label')
>>>
>>> fields = {'text': text, 'label': label}
>>> sst_train, sst_dev, sst_test = SST.get_dataset_splits(fields=fields)
>>> sst_train.finalize_fields()
>>>
>>> print(sst_train)
SST({
size: 6920,
fields: [
Field({
name: 'text',
keep_raw: False,
is_target: False,
vocab: Vocab({specials: ('<UNK>', '<PAD>'), eager: False, is_finalized: True, size: 5000})
}),
LabelField({
name: 'label',
keep_raw: False,
is_target: True,
vocab: Vocab({specials: (), eager: False, is_finalized: True, size: 2})
})
]
})
>>> print(sst_train[222])
Example({
text: (None, ['A', 'slick', ',', 'engrossing', 'melodrama', '.']),
label: (None, 'positive')
})
Each Dataset instance in the SST dataset splits contains Fields and a Vocab. When we pickle a dataset, we also store those objects. We will now demonstrate how to store (and load) a pickled dataset.
>>> from pathlib import Path
>>> import pickle
>>>
>>> cache_dir = Path('cache')
>>> cache_dir.mkdir()
>>>
>>> dataset_store_path = cache_dir.joinpath('sst_preprocessed.pkl')
>>>
>>> # Save the dataset
>>> with open(dataset_store_path, 'wb') as outfile:
... pickle.dump((sst_train, sst_dev, sst_test), outfile)
>>>
>>> # Restore the dataset
>>> with open(dataset_store_path, 'rb') as infile:
... sst_train, sst_dev, sst_test = pickle.load(infile)
>>> print(sst_train[222])
Example({
text: (None, ['A', 'slick', ',', 'engrossing', 'melodrama', '.']),
label: (None, 'positive')
})
Each of the components – Field, Vocab and Example can also be pickled separately. Apart from being able to save and load a Dataset and its components, you can also store an Iterator mid-iteration and it will continue on the batch on which you left off.
In case you don’t want this behavior and would rather your unpickled iterator starts from the beginning, you can call Iterator.reset() which will reset iterator to the start of the dataset.
>>> from podium import Iterator
>>> # Disable shuffling for consistency
>>> train_iter = Iterator(sst_train, batch_size=1, shuffle=False)
>>>
>>> batch = next(iter(train_iter))
>>> print(batch.text)
[[ 14 1144 9 2955 8 27 4 2956 3752 10 149 62 0 64
5 11 93 10 264 8 85 7 0 72 3753 38 2048 2957
3 0 3754 0 49 778 0 2]]
>>> iterator_store_path = cache_dir.joinpath('sst_train_iter.pkl')
>>> with open(iterator_store_path, 'wb') as outfile:
... pickle.dump((train_iter), outfile)
>>>
>>> with open(iterator_store_path, 'rb') as infile:
... train_iter_restore = pickle.load(infile)
Now that we have loaded our Iterator, we can validate whether the loaded version will continue where the initial one left off:
>>> restored_batch = next(iter(train_iter_restore))
>>> batch = next(iter(train_iter))
>>>
>>> import numpy as np
>>> print(np.array_equal(batch.text, restored_batch.text))
True
>>> print(np.array_equal(batch.label, restored_batch.label))
True
Of course, in case you want to start over, just call Iterator.reset() and the iteration will start from the beginning.